Transformer 是近年来自然语言处理(NLP)和生成式 AI 领域最重要的架构之一,自 2017 年提出以来,它已经成为大语言模型(LLM)、机器翻译、文本生成、图像生成等任务的核心基础。Transformer 架构的提出解决了传统循环神经网络(RNN)和卷积神经网络(CNN)在序列建模上的一些限制,使得模型能够高效处理长序列数据,并支持大规模并行训练。
一、Transformer 架构概览
Transformer 的核心思想是通过 自注意力机制(Self-Attention) 替代传统序列模型的循环操作,实现序列中任意位置的全局信息交互。与 RNN 不同,Transformer 不依赖于时间步的顺序计算,而是能够对整个序列同时进行并行处理。
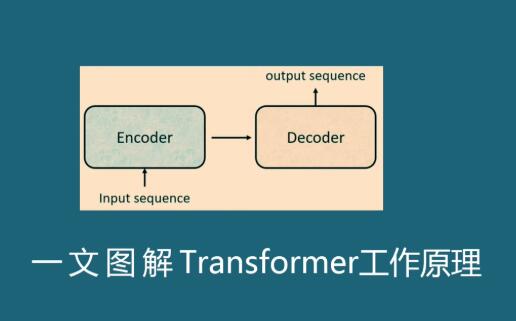
典型的 Transformer 架构主要分为两部分:
编码器(Encoder)
解码器(Decoder)
在机器翻译任务中,编码器用于理解源语言文本,解码器生成目标语言文本。但在大语言模型或自编码任务中,有些模型只使用编码器或解码器的部分架构。
二、编码器结构
编码器由若干重复堆叠的层组成,每一层包括以下模块:
自注意力层(Self-Attention Layer)
前馈全连接网络(Feed-Forward Network, FFN)
残差连接与层归一化(Residual & LayerNorm)
星宇智算官网GPU算力服务器租用–免费试用!

1. 自注意力机制
自注意力是 Transformer 的核心创新,它可以让序列中每个位置的表示与序列中所有其他位置进行信息交互。自注意力的计算过程可以概括为:
输入序列经过线性变换生成 查询(Query)、键(Key) 和 值(Value) 三个向量。
查询向量与所有键向量计算相似度(通常是点积),得到注意力权重。
将注意力权重与值向量加权求和,得到输出表示。
通过这种方式,每个位置的输出不仅包含自身信息,还融合了其他位置的上下文信息。
多头注意力
为了增强模型的表达能力,Transformer 使用 多头注意力(Multi-Head Attention),即将注意力机制分成多个子空间并行计算,然后将结果拼接。这允许模型在不同表示空间中捕捉不同类型的语义关系。
2. 前馈全连接网络
自注意力输出后,每个位置的向量会通过一个两层的前馈全连接网络进行非线性变换。这个模块的作用是对每个位置的表示进行进一步加工和特征提取,同时保持序列长度不变。
3. 残差连接与层归一化
在每个模块之后,Transformer 使用残差连接将输入与模块输出相加,并进行层归一化。这有助于:
避免梯度消失
加快模型训练收敛
提高深层堆叠网络的稳定性
三、解码器结构
解码器与编码器类似,但在生成序列时需要考虑已生成的内容,因此在每一层中增加 编码器-解码器注意力(Encoder-Decoder Attention)。
解码器的主要模块包括:
掩码自注意力层(Masked Self-Attention)
编码器-解码器注意力层(Cross Attention)
前馈全连接网络
残差连接与层归一化
1. 掩码自注意力
在生成任务中,解码器不能访问未来的词,因此引入掩码机制,屏蔽掉当前位置之后的序列信息,保证生成是因果的。
2. 编码器-解码器注意力
该模块将解码器当前状态与编码器输出进行交互,使生成的每个位置能够参考源序列的上下文信息。这是序列到序列任务(如翻译)的关键环节。
四、位置编码
由于 Transformer 不使用循环或卷积,序列的顺序信息必须显式注入模型。为此,引入 位置编码(Positional Encoding):
对每个位置添加一个向量,表示它在序列中的位置
位置向量可以是正弦/余弦函数编码,也可以是可训练向量
与输入嵌入相加,使模型感知词序信息
位置编码是保证 Transformer 能处理顺序数据的关键。
五、Transformer 的工作原理流程
以文本生成任务为例,Transformer 的工作流程可以概括如下:
输入嵌入:将词或子词转化为向量表示,并加入位置编码。
编码器处理:输入序列通过编码器层层处理,自注意力捕获全局上下文。
解码器生成:解码器在掩码自注意力和交叉注意力作用下逐步生成输出序列,每一步参考编码器输出和已生成词。
输出概率:解码器最后通过线性层和 Softmax,将向量映射为词汇表上的概率分布,选择最可能的词作为输出。
迭代生成:将新生成词加入输入,重复解码过程,直到生成结束符或达到最大长度。
这种流程实现了 高效的序列建模、全局上下文捕获和并行计算能力。
六、Transformer 的优势
Transformer 相比传统 RNN/CNN 模型有多个显著优势:
高并行性
由于不依赖时间步计算,序列可以一次性并行处理,训练速度大幅提升。
长序列建模能力强
自注意力机制允许每个位置直接关注序列中任意位置,解决 RNN 长依赖问题。
可扩展性强
可以通过堆叠更多层和增加注意力头来提升模型容量,适应大规模数据和复杂任务。
通用性
不仅适用于 NLP,还可扩展到图像、音频、图像-文本多模态任务。
七、Transformer 的应用场景
Transformer 的成功使它成为现代 AI 的核心技术:
机器翻译:如 Google Translate 的核心架构
文本生成:大语言模型(GPT 系列)
文本理解:BERT 系列用于问答、情感分析
图像生成与处理:Vision Transformer(ViT)
多模态任务:图文生成、视频理解
可以说,Transformer 是现代深度学习几乎所有序列和多模态任务的基础。
FAQ:Transformer 架构常见问题
Q1:Transformer 和 RNN 有什么区别?
Transformer 使用自注意力机制并行处理序列,而 RNN 是顺序计算,难以处理长序列依赖,训练速度慢。
Q2:多头注意力的作用是什么?
它允许模型在不同表示子空间中捕捉多种语义关系,提高表达能力。
Q3:为什么需要位置编码?
Transformer 不使用循环或卷积,位置编码提供序列顺序信息,让模型理解词序关系。
Q4:编码器和解码器可以单独使用吗?
可以。BERT 只使用编码器用于理解任务,GPT 只使用解码器用于生成任务。
Q5:Transformer 模型为什么训练需要大量数据和算力?
因为每一层都包含多头注意力和全连接网络,参数量巨大,并行计算需要强大 GPU 支持。
Q6:Transformer 能处理多模态任务吗?
可以,经过修改后可处理图像、音频或图文混合输入,如 CLIP、DALL·E、Video Transformer 等。
Transformer 架构通过自注意力、多头注意力和前馈网络,实现了高效的序列建模和全局信息交互。它突破了 RNN 在长依赖问题上的局限,并支持大规模并行训练,使得现代 NLP 和生成式 AI 技术成为可能。编码器和解码器的组合提供了灵活的架构设计,使 Transformer 能同时适用于理解、生成和多模态任务。理解 Transformer 的结构与工作原理,是掌握大语言模型和生成式 AI 的关键基础。

